Example for a Sick-Sicker-Dead model
Javier Sanchez Alvarez and Valerie Aponte Ribero
June 30, 2026
Source:vignettes/example_ssd.Rmd
example_ssd.RmdIntroduction
This document runs a discrete event simulation model in the context of a late oncology model to show how the functions can be used to generate a model in only a few steps.
When running a DES, it’s important to consider speed. Simulation based models can be computationally expensive, which means that using efficient coding can have a substantial impact on performance.
Main options
library(WARDEN)
library(dplyr)
#>
#> Attaching package: 'dplyr'
#> The following objects are masked from 'package:stats':
#>
#> filter, lag
#> The following objects are masked from 'package:base':
#>
#> intersect, setdiff, setequal, union
library(ggplot2)
library(kableExtra)
#>
#> Attaching package: 'kableExtra'
#> The following object is masked from 'package:dplyr':
#>
#> group_rows
library(purrr)General inputs with delayed execution
Initial inputs and flags that will be used in the model can be
defined below. We can define inputs that will only change across
scenarios (sensitivity_inputs), inputs which are common to
all patients (common_all_inputs) within a simulation,
inputs that are unique to a patient independently of the treatment
(e.g. natural time to death, defined in common_pt_inputs),
and inputs that are unique to that patient and that treatment
(unique_pt_inputs). Items can be included through the
add_item() function, and can be used in subsequent items.
All these inputs are generated before the events and the reaction to
events are executed. Furthermore, the program first executes
common_all_inputs, then common_pt_inputs and
then unique_pt_inputs. So one could use the items generated
in common_all_inputs in unique_pt_inputs. Note
that inputs are “reset” after each patient, so if patient 1 arm “noint”
changes util.sick to be = 2, even if it’s a common
parameter for everyone, it would be reset to 1 for patient 1 arm
“int”.
Note that time to death is set in the common_pt_inputs, but it could
also just be set in the add_tte function explained below.
The user has full flexibility on how to implement this type of
inputs.
There are some auxiliary functions to help setting up inputs, like
input_block() (and pick_psa(), see below the
section on Sensitivity Analysis).
Note that input_block() can be directly loaded as
parameters (in fact, a named list will be loaded directly by R).
#We don't need to use sensitivity_inputs here, so we don't add that object
#Put objects here that do not change on any patient or intervention loop
#We use add_item and add_item to showcase how the user can implement the inputs (either works, add_item is just faster)
common_all_inputs <-add_item(input = {
util.sick <- 0.8
util.sicker <- 0.5
cost.sick <- 3000
cost.sicker <- 7000
cost.int <- 1000
coef_noint <- log(0.2)
coef_death <- log(0.05)
HR_int <- 0.7
drc <- 0.035 #different values than what's assumed by default
drq <- 0.035
random_seed_sicker_i <- sample.int(100000,npats,replace = FALSE)
random_seed_death_i <- runif(npats)
}) #to be used as seeds to draw the time to event for sicker, to ensure same luck for the same patient independently of the arm
#Put objects here that do not change as we loop through treatments for a patient
common_pt_inputs <- add_item(death= qexp(random_seed_death_i[i], exp(coef_death)))
#Put objects here that change as we loop through treatments for each patient (e.g. events can affect fl.tx, but events do not affect nat.os.s)
unique_pt_inputs <- add_item(fl.sick = 1,
q_default = util.sick,
c_default = cost.sick + if(arm=="int"){cost.int}else{0}) Events
Add Initial Events
Events are added below through the add_tte() function.
We use this function once applying to both interventions. We must define
several arguments: one to indicate the intervention, one to define the
names of the events used, one to define the names of other objects
created that we would like to store (optional, maybe we generate an
intermediate input which is not an event but that we want to save) and
the actual input in which we generate the time to event. Events and
other objects will be automatically initialized to Inf. We
draw the times to event for the patients. Note: the order of the
evts argument that appears first will be used as a
reference of the order in which to process events in the case of ties
(so “sick” would be processed before “sicker” if there is a tie in time
to event.)
Note that the model will use the evnets defined in evts
argument to look for the objects both defined in the input list and in
this expression to allocate time to events. If an event is declared in
evts but not defined elsewhere, then they would be assumed
TTE of Inf by default.
This chunk is a bit more complex, so it’s worth spending a bit of time explaining it.
The init_event_list object is populated by using the
add_tte() function which applies to both arms, “int”
strategy and “noint” strategy. We first declare the start
time to be 0. Note this could also be separated by arm if
the user wants to have more clarity using two add_tte
functions (i.e.,
add_tte(arm="noint"...) |> add_tte(arm="int"...)).
We then proceed to generate the actual time to event. We use the
draw_tte() function to generate the time to event, though
one can set this up in any other way (e.g., using rexp()).
One should always be aware of how the competing risks interact with each
other. While we have abstracted from these type of corrections here, it
is recommended to have an understanding about how these affect the
results and have a look at the competing risks/semi-competing risks
literature.
init_event_list <-
add_tte(arm=c("noint","int"), evts = c("sick","sicker","death") ,input={
sick <- 0
sicker <- draw_tte(1,dist="exp", coef1=coef_noint, beta_tx = ifelse(arm=="int",HR_int,1), seed = random_seed_sicker_i[i]) #this way the value would be the same if it wasn't for the HR, effectively "cloning" patients luck
})Add Reaction to Those Events
Once the initial times of the events have been defined, we also need
to declare how events react and affect each other. To do so, we use the
evt_react_list object and the add_reactevt()
function. This function just needs to state which event is affected, and
the actual reaction (usually setting flags to 1 or 0, or creating
new/adjusting events).
There are a series of objects that can be used in this context to
help with the reactions. Apart from the global objects and flags defined
above, we can also use curtime for the current event time,
prevtime for the time of the previous event,
cur_evtlist for the C++ event queue, arm for
the current treatment in the loop, evt for the current
event being processed, i expresses the patient iteration,
and simulation the specific simulation (relevant when the
number of simulations is greater than 1). Furthermore, one can also call
any other input/item that has been created before or create new ones.
For example, we could even modify a cost/utility item by changing it
directly, e.g. through assigning it directly
cost.idfs.tx <- 500.
| Item | What does it do |
|---|---|
curtime |
Current event time (numeric) |
prevtime |
Time of the previous event (numeric) |
cur_evtlist |
External pointer of C++ events that is yet to happen for that patient |
evt |
Current event being processed (character) |
i |
Patient being iterated (numeric) |
arm |
Intervention being iterated (character) |
simulation |
Simulation being iterated (numeric) |
sens |
Sensitivity analysis being iterated (numeric) |
The functions to add/modify events and inputs use named vectors or
lists. Whenever several inputs/events are added or modified, it’s
recommended to group them within one function, as it reduces the
computation cost. So rather than use two modify_event()
with a list of one element, it’s better to group them into a single
modify_event() with a list of two elements.
The list of relevant functions to be used within
add_reactevt() are: new_event()allows to
generate events and add them to the vector of events. It accepts more
than one event but a single event per event type.
modify_event() allows to modify events (e.g. delay death).
When adding an event, the name of the events and the time of the events
must be defined. When using modify_event, one must indicate
which events are affected and what are the new times of the events. If
the event specified does not exist or has already occurred, it will
return an error. modify_event with
create_if_null = TRUE argument will also generate events if
they don’t exist. remove_event() will remove an event from
the event queue (could also be modified instead and set to
Inf). get_event() will return the TTE of the
specified event name. has_event() will return a TRUE/FALSE
flag depending on whether the given patient has a specific event in the
queue (will return TRUE even if time is Inf).
next_event() will return a list with the next event in the
queue, with time, patient, and event name (patient_id,
event_name, and time).
next_event_pt() will return a list with the next event in
the queue for a specific patient, with time, patient, and event name
(patient_id, event_name, and
time). queue_empty() will return TRUE if the
queue of events is empty (no more events to process, but
Inf events are considered part of the queue)
queue_size() allows to check the size of the queue of
events, including Inf events.
Note that one could potentially omit part of the modeling set in
init_event_list and actually define new events dynamically
through the reactions (we do that below for the "ae"
event). However, this can have an impact in computation time, so if
possible it’s always better to use init_event_list.
To modify/create items, WARDEN now allows to assign them directly in the code, which allows the code to run faster.
The model will run until curtime is set to
Inf, so the event that terminates the model (in this case,
os), should modify curtime and set it to
Inf.
Finally, note that there could be two different ways of accumulating
continuous outcomes, backwards (i.e., in the example below, we would set
q_default = util.sick at the sicker event, and modify the
q_default value in the death event) and forwards (as in the
example below). This option can be modified in the
run_sim() function using the accum_backwards
argument, which assumes forwards by default.
evt_react_list <-
add_reactevt(name_evt = "sick",
input = {}) |>
add_reactevt(name_evt = "sicker",
input = {
q_default <- util.sicker
c_default <- cost.sicker + if(arm=="int"){cost.int}else{0}
fl.sick <- 0
modify_event(c(
"death" = max(
curtime + (get_event("death")-curtime)*0.8,
curtime)))
}) |>
add_reactevt(name_evt = "death",
input = {
q_default <- 0
c_default <- 0
curtime <- Inf
})
# Below how it would be set up if using `accum_backwards = TRUE` in `run_sim()` (and will give equal final results)
# Note that we set the value applied in the reaction right up to the event, changing the interpretation of the reaction
# It is also a slower method than the standard approach
#
# evt_react_list <-
# add_reactevt(name_evt = "sick",
# input = {}) |>
# add_reactevt(name_evt = "sicker",
# input = {
# q_default = util.sick
# c_default = cost.sick + if(arm=="int"){cost.int}else{0}
# fl.sick = 0
# modify_event(c("death" = max(get_event("death") - 0.5,curtime)))
#
# }) |>
# add_reactevt(name_evt = "death",
# input = {
# c_dis <- if(fl.sick==1){cost.sick}else{cost.sicker}
# q_default = if(fl.sick==1){util.sick}else{util.sicker}
# c_default = c_dis + if(arm=="int"){cost.int}else{0}
# curtime = Inf
# }) Extract Interactions Within Events
As an additional optional step, to easily see the interactions
between the reactions of the events, we can also now use the
extract_from_reactions() function to obtain a data.frame
with all the relationships defined in the reactions in the model. This
functions looks at all assignments (through <- or
= or assign), modify_event() and
new_event() and checks which elements are being defined
there, their definition, and whether they are triggered conditionally
(e.g., "if(a == 1){b = 2}"). Note it would be
straightforward to build a network graph showcasing all the interactions
between events in terms of events affecting other events, or to show
which (and how) events affect specific items.
df_interactions <- extract_from_reactions(evt_react_list)
kable(df_interactions)| event | name | type | conditional_flag | definition |
|---|---|---|---|---|
| sicker | q_default | item | FALSE | util.sicker |
| sicker | c_default | item | FALSE | cost.sicker + if (arm == ‘int’) {cost.int} else {0} |
| sicker | fl.sick | item | FALSE | 0 |
| sicker | death | event | FALSE | max(curtime + (get_event(‘death’) - curtime) * 0.8, curtime) |
| death | q_default | item | FALSE | 0 |
| death | c_default | item | FALSE | 0 |
| death | curtime | item | FALSE | Inf |
Costs and Utilities
Costs and utilities are introduced below. However, it’s worth noting that the model is able to run without costs or utilities.
Utilities/Costs/Other outputs are defined by declaring which object
belongs to utilities/costs/other outputs, and whether they need to be
discounted continuously or discretely (instantaneous). These will be
passed to the run_sim() function.
Model
Model Execution
The model can be run using the function run_sim() below.
We must define the number of patients to be simulated, the number of
simulations, whether we want to run a PSA or not, the strategy list, the
inputs, events and reactions defined above, utilities, costs and also if
we want any extra output and the level of ipd data desired to be
exported.
It is worth noting that the psa_bool argument does not
run a PSA automatically, but is rather an additional input/flag of the
model that we use as a reference to determine whether we want to use a
deterministic or stochastic input. As such, it could also be defined in
common_all_inputs as the first item to be defined, and the
result would be the same. However, we recommend it to be defined in
run_sim().
Note that the distribution chosen, the number of events and the interaction between events can have a substantial impact on the running time of the model.
Debugging can be implemented using the argument debug in
the run_sim() function.
#Logic is: per patient, per intervention, per event, react to that event.
results <- run_sim(
npats=1000, # number of patients to be simulated
n_sim=1, # number of simulations to run
psa_bool = FALSE, # use PSA or not. If n_sim > 1 and psa_bool = FALSE, then difference in outcomes is due to sampling (number of pats simulated)
arm_list = c("int", "noint"), # intervention list
common_all_inputs = common_all_inputs, # inputs common that do not change within a simulation
common_pt_inputs = common_pt_inputs, # inputs that change within a simulation but are not affected by the intervention
unique_pt_inputs = unique_pt_inputs, # inputs that change within a simulation between interventions
init_event_list = init_event_list, # initial event list
evt_react_list = evt_react_list, # reaction of events
util_ongoing_list = util_ongoing,
cost_ongoing_list = cost_ongoing,
ipd = 1
)
#> Analysis number: 1
#> Simulation number: 1
#> Time to run simulation 1: 0.68s
#> Time to run analysis 1: 0.68s
#> Total time to run: 0.68s
#> Simulation finalized;Post-processing of Model Outputs
Summary of Results
Once the model has been run, we can use the results and summarize
them using the summary_results_det() to print the results
of the last simulation (if nsim = 1, it’s the deterministic
case), and summary_results_sim() to show the PSA results
(with the confidence intervals). We can also use the individual patient
data generated by the simulation, which we collect here to plot in the
psa_ipd object.
summary_results_det(results[[1]][[1]]) #print first simulation
#> int noint
#> costs 71261.66 63063.40
#> dcosts 0.00 8198.25
#> lys 11.21 11.08
#> dlys 0.00 0.12
#> qalys 6.98 6.63
#> dqalys 0.00 0.35
#> ICER NA 66484.18
#> ICUR NA 23296.79
#> INMB NA 9396.99
#> costs_undisc 118130.54 104038.82
#> dcosts_undisc 0.00 14091.72
#> lys_undisc 17.48 17.22
#> dlys_undisc 0.00 0.26
#> qalys_undisc 10.37 9.85
#> dqalys_undisc 0.00 0.52
#> ICER_undisc NA 54006.07
#> ICUR_undisc NA 27003.04
#> INMB_undisc NA 12001.13
#> c_default 71261.66 63063.40
#> dc_default 0.00 8198.25
#> c_default_undisc 118130.54 104038.82
#> dc_default_undisc 0.00 14091.72
#> q_default 6.98 6.63
#> dq_default 0.00 0.35
#> q_default_undisc 10.37 9.85
#> dq_default_undisc 0.00 0.52
summary_results_sim(results[[1]])
#> int noint
#> costs 71,262 (71,262; 71,262) 63,063 (63,063; 63,063)
#> dcosts 0 (0; 0) 8,198 (8,198; 8,198)
#> lys 11.2 (11.2; 11.2) 11.1 (11.1; 11.1)
#> dlys 0 (0; 0) 0.123 (0.123; 0.123)
#> qalys 6.98 (6.98; 6.98) 6.63 (6.63; 6.63)
#> dqalys 0 (0; 0) 0.352 (0.352; 0.352)
#> ICER NaN (NA; NA) 66,484 (66,484; 66,484)
#> ICUR NaN (NA; NA) 23,297 (23,297; 23,297)
#> INMB NaN (NA; NA) 9,397 (9,397; 9,397)
#> costs_undisc 118,131 (118,131; 118,131) 104,039 (104,039; 104,039)
#> dcosts_undisc 0 (0; 0) 14,092 (14,092; 14,092)
#> lys_undisc 17.5 (17.5; 17.5) 17.2 (17.2; 17.2)
#> dlys_undisc 0 (0; 0) 0.261 (0.261; 0.261)
#> qalys_undisc 10.4 (10.4; 10.4) 9.85 (9.85; 9.85)
#> dqalys_undisc 0 (0; 0) 0.522 (0.522; 0.522)
#> ICER_undisc NaN (NA; NA) 54,006 (54,006; 54,006)
#> ICUR_undisc NaN (NA; NA) 27,003 (27,003; 27,003)
#> INMB_undisc NaN (NA; NA) 12,001 (12,001; 12,001)
#> c_default 71,262 (71,262; 71,262) 63,063 (63,063; 63,063)
#> dc_default 0 (0; 0) 8,198 (8,198; 8,198)
#> c_default_undisc 118,131 (118,131; 118,131) 104,039 (104,039; 104,039)
#> dc_default_undisc 0 (0; 0) 14,092 (14,092; 14,092)
#> q_default 6.98 (6.98; 6.98) 6.63 (6.63; 6.63)
#> dq_default 0 (0; 0) 0.352 (0.352; 0.352)
#> q_default_undisc 10.4 (10.4; 10.4) 9.85 (9.85; 9.85)
#> dq_default_undisc 0 (0; 0) 0.522 (0.522; 0.522)
summary_results_sens(results)
#> arm analysis analysis_name variable value
#> <char> <int> <char> <fctr> <char>
#> 1: int 1 costs 71,262 (71,262; 71,262)
#> 2: noint 1 costs 63,063 (63,063; 63,063)
#> 3: int 1 dcosts 0 (0; 0)
#> 4: noint 1 dcosts 8,198 (8,198; 8,198)
#> 5: int 1 lys 11.2 (11.2; 11.2)
#> 6: noint 1 lys 11.1 (11.1; 11.1)
#> 7: int 1 dlys 0 (0; 0)
#> 8: noint 1 dlys 0.123 (0.123; 0.123)
#> 9: int 1 qalys 6.98 (6.98; 6.98)
#> 10: noint 1 qalys 6.63 (6.63; 6.63)
#> 11: int 1 dqalys 0 (0; 0)
#> 12: noint 1 dqalys 0.352 (0.352; 0.352)
#> 13: int 1 ICER NaN (NA; NA)
#> 14: noint 1 ICER 66,484 (66,484; 66,484)
#> 15: int 1 ICUR NaN (NA; NA)
#> 16: noint 1 ICUR 23,297 (23,297; 23,297)
#> 17: int 1 INMB NaN (NA; NA)
#> 18: noint 1 INMB 9,397 (9,397; 9,397)
#> 19: int 1 costs_undisc 118,131 (118,131; 118,131)
#> 20: noint 1 costs_undisc 104,039 (104,039; 104,039)
#> 21: int 1 dcosts_undisc 0 (0; 0)
#> 22: noint 1 dcosts_undisc 14,092 (14,092; 14,092)
#> 23: int 1 lys_undisc 17.5 (17.5; 17.5)
#> 24: noint 1 lys_undisc 17.2 (17.2; 17.2)
#> 25: int 1 dlys_undisc 0 (0; 0)
#> 26: noint 1 dlys_undisc 0.261 (0.261; 0.261)
#> 27: int 1 qalys_undisc 10.4 (10.4; 10.4)
#> 28: noint 1 qalys_undisc 9.85 (9.85; 9.85)
#> 29: int 1 dqalys_undisc 0 (0; 0)
#> 30: noint 1 dqalys_undisc 0.522 (0.522; 0.522)
#> 31: int 1 ICER_undisc NaN (NA; NA)
#> 32: noint 1 ICER_undisc 54,006 (54,006; 54,006)
#> 33: int 1 ICUR_undisc NaN (NA; NA)
#> 34: noint 1 ICUR_undisc 27,003 (27,003; 27,003)
#> 35: int 1 INMB_undisc NaN (NA; NA)
#> 36: noint 1 INMB_undisc 12,001 (12,001; 12,001)
#> 37: int 1 c_default 71,262 (71,262; 71,262)
#> 38: noint 1 c_default 63,063 (63,063; 63,063)
#> 39: int 1 dc_default 0 (0; 0)
#> 40: noint 1 dc_default 8,198 (8,198; 8,198)
#> 41: int 1 c_default_undisc 118,131 (118,131; 118,131)
#> 42: noint 1 c_default_undisc 104,039 (104,039; 104,039)
#> 43: int 1 dc_default_undisc 0 (0; 0)
#> 44: noint 1 dc_default_undisc 14,092 (14,092; 14,092)
#> 45: int 1 q_default 6.98 (6.98; 6.98)
#> 46: noint 1 q_default 6.63 (6.63; 6.63)
#> 47: int 1 dq_default 0 (0; 0)
#> 48: noint 1 dq_default 0.352 (0.352; 0.352)
#> 49: int 1 q_default_undisc 10.4 (10.4; 10.4)
#> 50: noint 1 q_default_undisc 9.85 (9.85; 9.85)
#> 51: int 1 dq_default_undisc 0 (0; 0)
#> 52: noint 1 dq_default_undisc 0.522 (0.522; 0.522)
#> arm analysis analysis_name variable value
#> <char> <int> <char> <fctr> <char>
psa_ipd <- bind_rows(map(results[[1]], "merged_df"))
psa_ipd[1:10,] |>
kable() |>
kable_styling(bootstrap_options = c("striped", "hover", "condensed", "responsive"))| evtname | evttime | prevtime | pat_id | arm | total_lys | total_qalys | total_costs | total_costs_undisc | total_qalys_undisc | total_lys_undisc | lys | qalys | costs | lys_undisc | qalys_undisc | costs_undisc | c_default | q_default | c_default_undisc | q_default_undisc | nexttime | simulation | sensitivity |
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| sick | 0.000 | 0.000 | 1 | int | 1.965 | 1.572 | 7860 | 8138 | 1.628 | 2.034 | 1.965 | 1.572 | 7860 | 2.034 | 1.628 | 8138 | 7860 | 1.572 | 8138 | 1.628 | 2.034 | 1 | 1 |
| death | 2.034 | 0.000 | 1 | int | 1.965 | 1.572 | 7860 | 8138 | 1.628 | 2.034 | 0.000 | 0.000 | 0 | 0.000 | 0.000 | 0 | 0 | 0.000 | 0 | 0.000 | 2.034 | 1 | 1 |
| sick | 0.000 | 0.000 | 2 | int | 4.811 | 2.709 | 34439 | 37953 | 2.938 | 5.259 | 1.012 | 0.809 | 4047 | 1.030 | 0.824 | 4119 | 4047 | 0.809 | 4119 | 0.824 | 1.030 | 1 | 1 |
| sicker | 1.030 | 0.000 | 2 | int | 4.811 | 2.709 | 34439 | 37953 | 2.938 | 5.259 | 3.799 | 1.900 | 30392 | 4.229 | 2.115 | 33834 | 30392 | 1.900 | 33834 | 2.115 | 5.259 | 1 | 1 |
| death | 5.259 | 1.030 | 2 | int | 4.811 | 2.709 | 34439 | 37953 | 2.938 | 5.259 | 0.000 | 0.000 | 0 | 0.000 | 0.000 | 0 | 0 | 0.000 | 0 | 0.000 | 5.259 | 1 | 1 |
| sick | 0.000 | 0.000 | 3 | int | 0.807 | 0.512 | 5011 | 5094 | 0.518 | 0.819 | 0.362 | 0.289 | 1446 | 0.364 | 0.291 | 1455 | 1446 | 0.289 | 1455 | 0.291 | 0.364 | 1 | 1 |
| sicker | 0.364 | 0.000 | 3 | int | 0.807 | 0.512 | 5011 | 5094 | 0.518 | 0.819 | 0.446 | 0.223 | 3565 | 0.455 | 0.227 | 3638 | 3565 | 0.223 | 3638 | 0.227 | 0.819 | 1 | 1 |
| death | 0.819 | 0.364 | 3 | int | 0.807 | 0.512 | 5011 | 5094 | 0.518 | 0.819 | 0.000 | 0.000 | 0 | 0.000 | 0.000 | 0 | 0 | 0.000 | 0 | 0.000 | 0.819 | 1 | 1 |
| sick | 0.000 | 0.000 | 4 | int | 9.356 | 5.738 | 60714 | 75252 | 6.775 | 11.290 | 3.533 | 2.826 | 14131 | 3.767 | 3.013 | 15066 | 14131 | 2.826 | 15066 | 3.013 | 3.767 | 1 | 1 |
| sicker | 3.767 | 0.000 | 4 | int | 9.356 | 5.738 | 60714 | 75252 | 6.775 | 11.290 | 5.823 | 2.911 | 46583 | 7.523 | 3.762 | 60186 | 46583 | 2.911 | 60186 | 3.762 | 11.290 | 1 | 1 |
We can also check what has been the absolute number of events per strategy.
| arm | evtname | n |
|---|---|---|
| int | death | 1000 |
| int | sick | 1000 |
| int | sicker | 733 |
| noint | death | 1000 |
| noint | sick | 1000 |
| noint | sicker | 785 |
Plots
We now use the data output to plot the histograms/densities of the simulation.
data_plot <- results[[1]][[1]]$merged_df |>
filter(evtname != "sick") |>
group_by(arm,evtname,simulation) |>
mutate(median = median(evttime)) |>
ungroup()
ggplot(data_plot) +
geom_density(aes(fill = arm, x = evttime),
alpha = 0.7) +
geom_vline(aes(xintercept=median,col=arm)) +
facet_wrap( ~ evtname, scales = "free") +
scale_y_continuous(expand = c(0, 0)) +
scale_x_continuous(expand = c(0, 0)) +
theme_bw()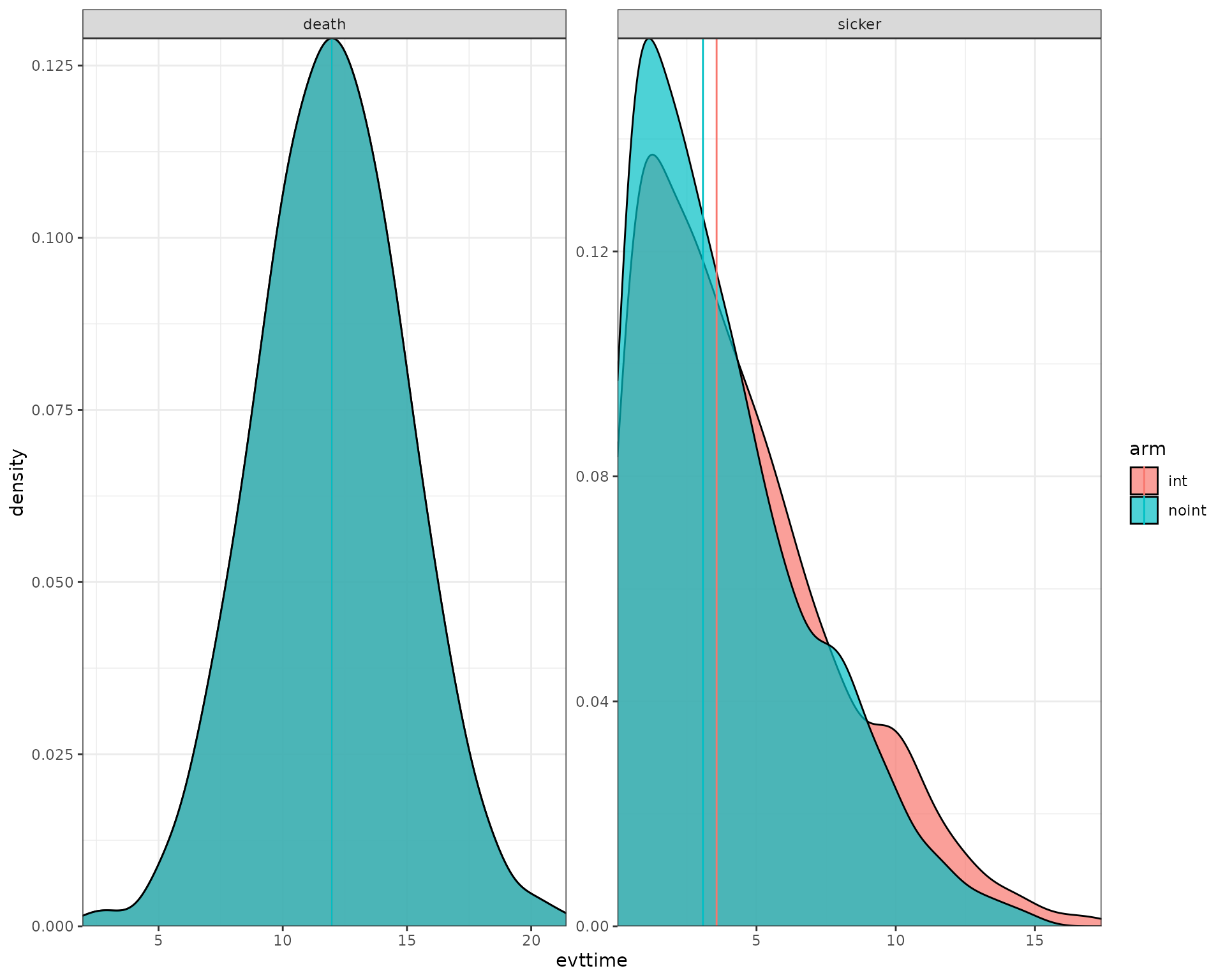
We can also plot the patient level incremental QALY/costs.
data_qaly_cost<- psa_ipd[,.SD[1],by=.(pat_id,arm,simulation)][,.(arm,qaly=total_qalys,cost=total_costs,pat_id,simulation)]
data_qaly_cost[,ps_id:=paste(pat_id,simulation,sep="_")]
mean_data_qaly_cost <- data_qaly_cost |> group_by(arm) |> summarise(across(where(is.numeric),mean))
ggplot(data_qaly_cost,aes(x=qaly, y = cost, col = arm)) +
geom_point(alpha=0.15,shape = 21) +
geom_point(data=mean_data_qaly_cost, aes(x=qaly, y = cost, fill = arm), shape = 21,col="black",size=3) +
scale_y_continuous(expand = c(0, 0)) +
scale_x_continuous(expand = c(0, 0)) +
theme_bw()+
theme(axis.text.x = element_text(angle = 90, vjust = .5))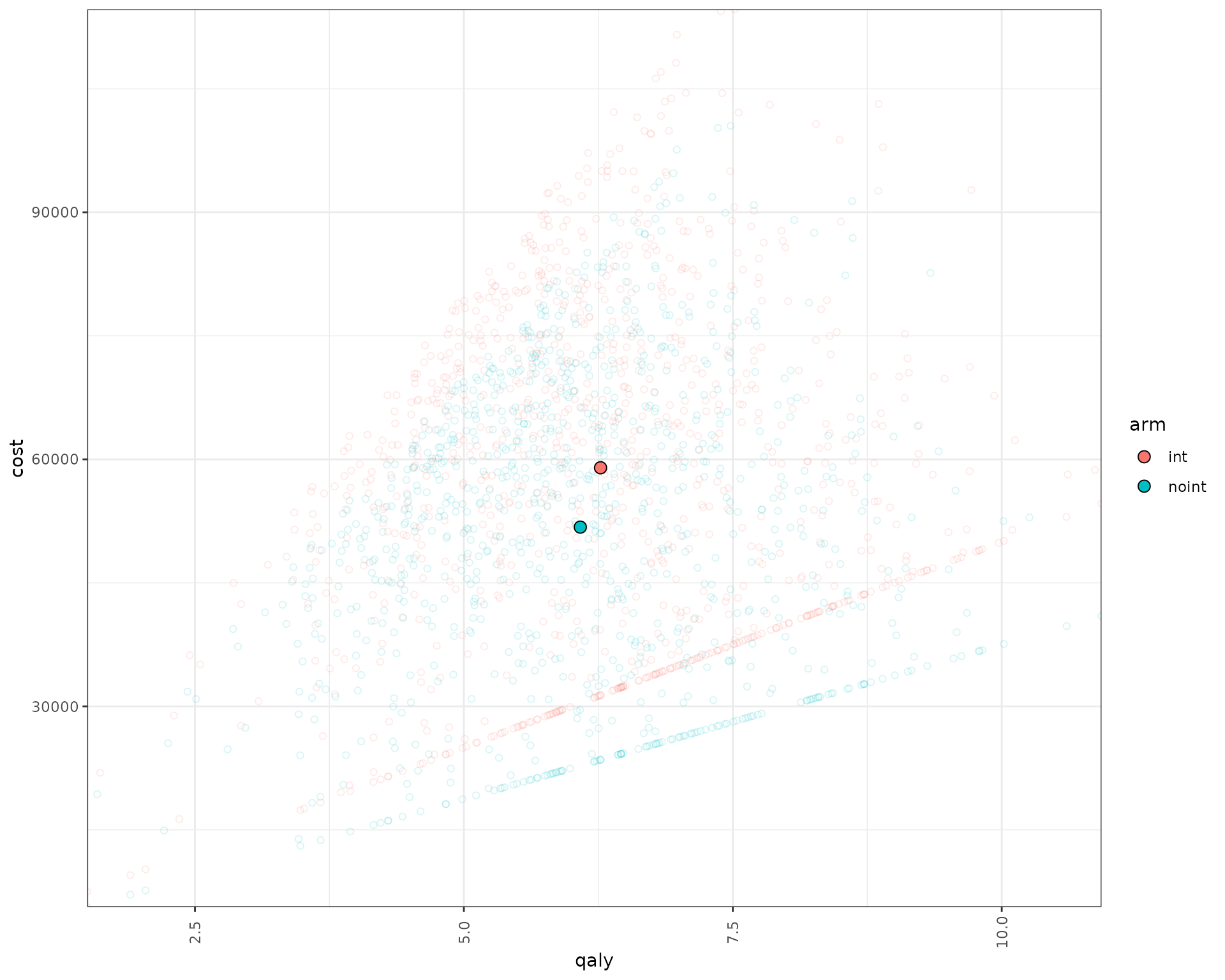
Sensitivity Analysis
Inputs
We use input_block() (from WARDEN v2.02) to simplify the
approach on how to automatically manage PSA and DSA.
pick_psa can be used to select the correct PSA
distributions.
#Load some data
list_par <- list(parameter_name = list("util.sick","util.sicker","cost.sick","cost.sicker","cost.int","coef_noint","coef_death","HR_int"),
base_value = list(0.8,0.5,3000,7000,1000,log(0.2),log(0.05),0.7),
DSA_min = list(0.6,0.3,1000,5000,800,log(0.1),log(0.1),0.5),
DSA_max = list(0.9,0.7,5000,9000,2000,log(0.4),log(0.03),0.9),
PSA_dist = list("rnorm","rbeta_mse","rgamma_mse","rgamma_mse","rgamma_mse","rnorm","rnorm","rlnorm"),
a=list(0.8,0.5,3000,7000,1000,log(0.2),log(0.05),log(0.7)),
b=lapply(list(0.8,0.5,3000,7000,1000,log(0.2),log(0.05),log(0.7)), function(x) abs(x/5)),
scenario_1=list(0.6,0.3,1000,5000,800,log(0.1),log(0.03),0.5),
scenario_2=list(0.9,0.7,5000,9000,2000,log(0.4),log(0.2),log(0.1),0.9)
)
common_all_inputs <- input_block(
base = list_par[["base_value"]],
psa = pick_psa(list_par[["PSA_dist"]],rep(1,length(list_par[["PSA_dist"]])),list_par[["a"]],list_par[["b"]]),
sens = list_par,
names_out = list_par[["parameter_name"]],
dsa_names = c("DSA_min","DSA_max")
) |>
add_item(random_seed_sicker_i = sample(1:1000,1000,replace = FALSE),
random_seed_death_i <- runif(npats)) #we don't add these variables to the sensitivity analysisModel Execution
results <- run_sim(
npats=100, # number of patients to be simulated
n_sim=1, # number of simulations to run
psa_bool = FALSE, # use PSA or not. If n_sim > 1 and psa_bool = FALSE, then difference in outcomes is due to sampling (number of pats simulated)
arm_list = c("int", "noint"), # intervention list
common_all_inputs = common_all_inputs, # inputs common that do not change within a simulation
common_pt_inputs = common_pt_inputs, # inputs that change within a simulation but are not affected by the intervention
unique_pt_inputs = unique_pt_inputs, # inputs that change within a simulation between interventions
init_event_list = init_event_list, # initial event list
evt_react_list = evt_react_list, # reaction of events
util_ongoing_list = util_ongoing,
cost_ongoing_list = cost_ongoing,
sensitivity_names = c("DSA_min","DSA_max"),
sensitivity_bool = TRUE,
input_out = unlist(list_par[["parameter_name"]])
)
#> n_sensitivity auto-detected as 8 from input_block metadata
#> Analysis number: 1
#> Simulation number: 1
#> Time to run simulation 1: 0.12s
#> Time to run analysis 1: 0.13s
#> Analysis number: 2
#> Simulation number: 1
#> Time to run simulation 1: 0.13s
#> Time to run analysis 2: 0.13s
#> Analysis number: 3
#> Simulation number: 1
#> Time to run simulation 1: 0.13s
#> Time to run analysis 3: 0.13s
#> Analysis number: 4
#> Simulation number: 1
#> Time to run simulation 1: 0.13s
#> Time to run analysis 4: 0.13s
#> Analysis number: 5
#> Simulation number: 1
#> Time to run simulation 1: 0.13s
#> Time to run analysis 5: 0.13s
#> Analysis number: 6
#> Simulation number: 1
#> Time to run simulation 1: 0.13s
#> Time to run analysis 6: 0.13s
#> Analysis number: 7
#> Simulation number: 1
#> Time to run simulation 1: 0.12s
#> Time to run analysis 7: 0.13s
#> Analysis number: 8
#> Simulation number: 1
#> Time to run simulation 1: 0.13s
#> Time to run analysis 8: 0.13s
#> Analysis number: 9
#> Simulation number: 1
#> Time to run simulation 1: 0.13s
#> Time to run analysis 9: 0.13s
#> Analysis number: 10
#> Simulation number: 1
#> Time to run simulation 1: 0.13s
#> Time to run analysis 10: 0.13s
#> Analysis number: 11
#> Simulation number: 1
#> Time to run simulation 1: 0.13s
#> Time to run analysis 11: 0.13s
#> Analysis number: 12
#> Simulation number: 1
#> Time to run simulation 1: 0.13s
#> Time to run analysis 12: 0.14s
#> Analysis number: 13
#> Simulation number: 1
#> Time to run simulation 1: 0.18s
#> Time to run analysis 13: 0.18s
#> Analysis number: 14
#> Simulation number: 1
#> Time to run simulation 1: 0.13s
#> Time to run analysis 14: 0.13s
#> Analysis number: 15
#> Simulation number: 1
#> Time to run simulation 1: 0.14s
#> Time to run analysis 15: 0.14s
#> Analysis number: 16
#> Simulation number: 1
#> Time to run simulation 1: 0.13s
#> Time to run analysis 16: 0.14s
#> Total time to run: 2.18s
#> Simulation finalized;Alternative deprecated approach using pick_val_v and setting manually iterators
This approach does not use input_block(), but instead
needs to set manually the iterators as part of the sensitivity inputs,
and then declare pick_val_V() and the relevant arguments in
run_sim() It has been left as a valid approach to make sure
older models using WARDEN will still run.
In this case, inputs must be created first to change across
sensitivity analysis. To do so, the item list
sensitivity_inputs can be used. In this case, we also use
pick_val_v() which allows the model to automatically pick
the relevant value (no PSA, PSA or sensitivity analysis) based on the
corresponding boolean flags of psa_bool and sensitivity_bool. In this
case we also use the sens iterator for each sensitivity
analysis and the n_sensitivity which is an argument in
run_sim().
Note that we have then just changed how the inputs are handled in
common_all_inputs, but the same could be done with unique_pt_inputs, but
in those cases, as the inputs change per patient, the
pick_val_v()function should be applied within
unique_pt_inputs to make sure they are evaluated when it correspond.
Note that for the psa we are directly calling the distributions and
passing the parameters.Note also that the sens_name_used is
automatically computed by the engine and is accessible to the user (it’s
the name of the sensitivity analysis, e.g., “scenario 1”).
The indicator parameter in pick_val_v() is used to
determine which parameters are left “as is” and which ones are to be
substituted with the sensitivity value. There are two ways to do this,
either by setting it in a binary way (1 or 0), or by using the indicator
as the number of the parameter values to be varied (useful when several
parameters are varied at the same time, or only specific values of a
vector are varied). This can be set by using
indicator_sens_binary argument.
Note that pick_val_v() can be directly loaded as
parameters (in fact, a named list will be loaded directly by R). A small
tweak is needed if it’s the first item added, in which the item list
must be initiated by using add_item() (see below). Note
that one can use a list of lists in the case where the base_value or any
of the other parameters are vectors instead of elements of length 1. In
this case, we showcase a list but it could also use a data.frame.
The model is executed as before, just adding the
sensitivity_inputs, sensitivity_names,
sensitivity_bool and n_sensitivity arguments.
Note that the total number of sensitivity iterations is given not by
n_sensitivity, but by n_sensitivity * length(sensitivity_names), so in
this case it will be 2 x n_sensitivity, or 2 x 7 = 14. For two scenario
analysis it would be 2 x 1 = 2, with the indicators
variable defined in the previous section taking value 1 for all the
variables altered in the scenario, and 0 otherwise.
#ALTERNATIVE, OLD APPROACH
sensitivity_inputs <-add_item(
indicators = if(sensitivity_bool){ create_indicators(sens,n_sensitivity*length(sensitivity_names),rep(1,length(list_par[[1]])))}else{
rep(1,length(list_par[[1]]))} #vector of indicators, value 0 everywhere except at sens, where it takes value 1 (for dsa_min and dsa_max, if not sensitivity analysis, then we activate all of them, i.e., in a PSA)
)
common_all_inputs <- add_item(
pick_val_v(base = list_par[["base_value"]],
psa = pick_psa(list_par[["PSA_dist"]],rep(1,length(list_par[["PSA_dist"]])),list_par[["a"]],list_par[["b"]]),
sens = list_par[[sens_name_used]],
psa_ind = psa_bool,
sens_ind = sensitivity_bool,
indicator = indicators,
names_out = list_par[["parameter_name"]]
)
) |>
add_item(random_seed_sicker_i = sample(1:1000,1000,replace = FALSE),
random_seed_death_i <- runif(npats))
results <- run_sim(
npats=100, # number of patients to be simulated
n_sim=1, # number of simulations to run
psa_bool = FALSE, # use PSA or not. If n_sim > 1 and psa_bool = FALSE, then difference in outcomes is due to sampling (number of pats simulated)
arm_list = c("int", "noint"), # intervention list
common_all_inputs = common_all_inputs, # inputs common that do not change within a simulation
common_pt_inputs = common_pt_inputs, # inputs that change within a simulation but are not affected by the intervention
unique_pt_inputs = unique_pt_inputs, # inputs that change within a simulation between interventions
init_event_list = init_event_list, # initial event list
evt_react_list = evt_react_list, # reaction of events
util_ongoing_list = util_ongoing,
cost_ongoing_list = cost_ongoing,
sensitivity_inputs = sensitivity_inputs,
sensitivity_names = c("DSA_min","DSA_max"),
sensitivity_bool = TRUE,
n_sensitivity = length(list_par[[1]]),
input_out = unlist(list_par[["parameter_name"]])
)Check results
We briefly check below that indeed the engine has been changing the corresponding parameter value.
data_sensitivity <- bind_rows(map_depth(results,2, "merged_df"))
#Check mean value across iterations as PSA is off
data_sensitivity |> group_by(sensitivity) |> summarise_at(c("util.sick","util.sicker","cost.sick","cost.sicker","cost.int","coef_noint","coef_death","HR_int"),mean)
#> # A tibble: 16 × 9
#> sensitivity util.sick util.sicker cost.sick cost.sicker cost.int coef_noint
#> <int> <dbl> <dbl> <dbl> <dbl> <dbl> <dbl>
#> 1 1 0.6 0.5 3000 7000 1000 -1.61
#> 2 2 0.8 0.3 3000 7000 1000 -1.61
#> 3 3 0.8 0.5 1000 7000 1000 -1.61
#> 4 4 0.8 0.5 3000 5000 1000 -1.61
#> 5 5 0.8 0.5 3000 7000 800 -1.61
#> 6 6 0.8 0.5 3000 7000 1000 -2.30
#> 7 7 0.8 0.5 3000 7000 1000 -1.61
#> 8 8 0.8 0.5 3000 7000 1000 -1.61
#> 9 9 0.9 0.5 3000 7000 1000 -1.61
#> 10 10 0.8 0.7 3000 7000 1000 -1.61
#> 11 11 0.8 0.5 5000 7000 1000 -1.61
#> 12 12 0.8 0.5 3000 9000 1000 -1.61
#> 13 13 0.8 0.5 3000 7000 2000 -1.61
#> 14 14 0.8 0.5 3000 7000 1000 -0.916
#> 15 15 0.8 0.5 3000 7000 1000 -1.61
#> 16 16 0.8 0.5 3000 7000 1000 -1.61
#> # ℹ 2 more variables: coef_death <dbl>, HR_int <dbl>Model Execution, probabilistic DSA
The model is executed as before, just activating the psa_bool option
results <- run_sim(
npats=100,
n_sim=6,
psa_bool = TRUE,
arm_list = c("int", "noint"),
common_all_inputs = common_all_inputs,
common_pt_inputs = common_pt_inputs,
unique_pt_inputs = unique_pt_inputs,
init_event_list = init_event_list,
evt_react_list = evt_react_list,
util_ongoing_list = util_ongoing,
cost_ongoing_list = cost_ongoing,
sensitivity_bool = TRUE,
sensitivity_names = c("DSA_min","DSA_max"),
input_out = unlist(list_par[["parameter_name"]])
)
#> n_sensitivity auto-detected as 8 from input_block metadata
#> Analysis number: 1
#> Simulation number: 1
#> Time to run simulation 1: 0.14s
#> Simulation number: 2
#> Time to run simulation 2: 0.14s
#> Simulation number: 3
#> Time to run simulation 3: 0.14s
#> Simulation number: 4
#> Time to run simulation 4: 0.14s
#> Simulation number: 5
#> Time to run simulation 5: 0.33s
#> Simulation number: 6
#> Time to run simulation 6: 0.12s
#> Time to run analysis 1: 1.01s
#> Analysis number: 2
#> Simulation number: 1
#> Time to run simulation 1: 0.13s
#> Simulation number: 2
#> Time to run simulation 2: 0.13s
#> Simulation number: 3
#> Time to run simulation 3: 0.14s
#> Simulation number: 4
#> Time to run simulation 4: 0.12s
#> Simulation number: 5
#> Time to run simulation 5: 0.13s
#> Simulation number: 6
#> Time to run simulation 6: 0.12s
#> Time to run analysis 2: 0.78s
#> Analysis number: 3
#> Simulation number: 1
#> Time to run simulation 1: 0.13s
#> Simulation number: 2
#> Time to run simulation 2: 0.12s
#> Simulation number: 3
#> Time to run simulation 3: 0.13s
#> Simulation number: 4
#> Time to run simulation 4: 0.12s
#> Simulation number: 5
#> Time to run simulation 5: 0.13s
#> Simulation number: 6
#> Time to run simulation 6: 0.12s
#> Time to run analysis 3: 0.76s
#> Analysis number: 4
#> Simulation number: 1
#> Time to run simulation 1: 0.13s
#> Simulation number: 2
#> Time to run simulation 2: 0.12s
#> Simulation number: 3
#> Time to run simulation 3: 0.13s
#> Simulation number: 4
#> Time to run simulation 4: 0.12s
#> Simulation number: 5
#> Time to run simulation 5: 0.13s
#> Simulation number: 6
#> Time to run simulation 6: 0.12s
#> Time to run analysis 4: 0.76s
#> Analysis number: 5
#> Simulation number: 1
#> Time to run simulation 1: 0.13s
#> Simulation number: 2
#> Time to run simulation 2: 0.12s
#> Simulation number: 3
#> Time to run simulation 3: 0.13s
#> Simulation number: 4
#> Time to run simulation 4: 0.13s
#> Simulation number: 5
#> Time to run simulation 5: 0.12s
#> Simulation number: 6
#> Time to run simulation 6: 0.13s
#> Time to run analysis 5: 0.77s
#> Analysis number: 6
#> Simulation number: 1
#> Time to run simulation 1: 0.12s
#> Simulation number: 2
#> Time to run simulation 2: 0.13s
#> Simulation number: 3
#> Time to run simulation 3: 0.12s
#> Simulation number: 4
#> Time to run simulation 4: 0.13s
#> Simulation number: 5
#> Time to run simulation 5: 0.13s
#> Simulation number: 6
#> Time to run simulation 6: 0.12s
#> Time to run analysis 6: 0.76s
#> Analysis number: 7
#> Simulation number: 1
#> Time to run simulation 1: 0.13s
#> Simulation number: 2
#> Time to run simulation 2: 0.13s
#> Simulation number: 3
#> Time to run simulation 3: 0.12s
#> Simulation number: 4
#> Time to run simulation 4: 0.13s
#> Simulation number: 5
#> Time to run simulation 5: 0.13s
#> Simulation number: 6
#> Time to run simulation 6: 0.14s
#> Time to run analysis 7: 0.79s
#> Analysis number: 8
#> Simulation number: 1
#> Time to run simulation 1: 0.13s
#> Simulation number: 2
#> Time to run simulation 2: 0.13s
#> Simulation number: 3
#> Time to run simulation 3: 0.13s
#> Simulation number: 4
#> Time to run simulation 4: 0.13s
#> Simulation number: 5
#> Time to run simulation 5: 0.14s
#> Simulation number: 6
#> Time to run simulation 6: 0.15s
#> Time to run analysis 8: 0.82s
#> Analysis number: 9
#> Simulation number: 1
#> Time to run simulation 1: 0.13s
#> Simulation number: 2
#> Time to run simulation 2: 0.14s
#> Simulation number: 3
#> Time to run simulation 3: 0.13s
#> Simulation number: 4
#> Time to run simulation 4: 0.13s
#> Simulation number: 5
#> Time to run simulation 5: 0.13s
#> Simulation number: 6
#> Time to run simulation 6: 0.13s
#> Time to run analysis 9: 0.79s
#> Analysis number: 10
#> Simulation number: 1
#> Time to run simulation 1: 0.13s
#> Simulation number: 2
#> Time to run simulation 2: 0.14s
#> Simulation number: 3
#> Time to run simulation 3: 0.13s
#> Simulation number: 4
#> Time to run simulation 4: 0.14s
#> Simulation number: 5
#> Time to run simulation 5: 0.14s
#> Simulation number: 6
#> Time to run simulation 6: 0.13s
#> Time to run analysis 10: 0.8s
#> Analysis number: 11
#> Simulation number: 1
#> Time to run simulation 1: 0.14s
#> Simulation number: 2
#> Time to run simulation 2: 0.14s
#> Simulation number: 3
#> Time to run simulation 3: 0.13s
#> Simulation number: 4
#> Time to run simulation 4: 0.14s
#> Simulation number: 5
#> Time to run simulation 5: 0.14s
#> Simulation number: 6
#> Time to run simulation 6: 0.13s
#> Time to run analysis 11: 0.81s
#> Analysis number: 12
#> Simulation number: 1
#> Time to run simulation 1: 0.14s
#> Simulation number: 2
#> Time to run simulation 2: 0.14s
#> Simulation number: 3
#> Time to run simulation 3: 0.15s
#> Simulation number: 4
#> Time to run simulation 4: 0.13s
#> Simulation number: 5
#> Time to run simulation 5: 0.14s
#> Simulation number: 6
#> Time to run simulation 6: 0.13s
#> Time to run analysis 12: 0.83s
#> Analysis number: 13
#> Simulation number: 1
#> Time to run simulation 1: 0.14s
#> Simulation number: 2
#> Time to run simulation 2: 0.14s
#> Simulation number: 3
#> Time to run simulation 3: 0.13s
#> Simulation number: 4
#> Time to run simulation 4: 0.14s
#> Simulation number: 5
#> Time to run simulation 5: 0.14s
#> Simulation number: 6
#> Time to run simulation 6: 0.13s
#> Time to run analysis 13: 0.83s
#> Analysis number: 14
#> Simulation number: 1
#> Time to run simulation 1: 0.14s
#> Simulation number: 2
#> Time to run simulation 2: 0.14s
#> Simulation number: 3
#> Time to run simulation 3: 0.14s
#> Simulation number: 4
#> Time to run simulation 4: 0.13s
#> Simulation number: 5
#> Time to run simulation 5: 0.16s
#> Simulation number: 6
#> Time to run simulation 6: 0.33s
#> Time to run analysis 14: 1.05s
#> Analysis number: 15
#> Simulation number: 1
#> Time to run simulation 1: 0.12s
#> Simulation number: 2
#> Time to run simulation 2: 0.13s
#> Simulation number: 3
#> Time to run simulation 3: 0.12s
#> Simulation number: 4
#> Time to run simulation 4: 0.13s
#> Simulation number: 5
#> Time to run simulation 5: 0.12s
#> Simulation number: 6
#> Time to run simulation 6: 0.13s
#> Time to run analysis 15: 0.77s
#> Analysis number: 16
#> Simulation number: 1
#> Time to run simulation 1: 0.12s
#> Simulation number: 2
#> Time to run simulation 2: 0.13s
#> Simulation number: 3
#> Time to run simulation 3: 0.12s
#> Simulation number: 4
#> Time to run simulation 4: 0.13s
#> Simulation number: 5
#> Time to run simulation 5: 0.12s
#> Simulation number: 6
#> Time to run simulation 6: 0.13s
#> Time to run analysis 16: 0.76s
#> Total time to run: 13.09s
#> Simulation finalized;Check results
We briefly check below that indeed the engine has been changing the corresponding parameter value.
data_sensitivity <- bind_rows(map_depth(results,2, "merged_df"))
#Check mean value across iterations as PSA is off
data_sensitivity |> group_by(sensitivity) |> summarise_at(c("util.sick","util.sicker","cost.sick","cost.sicker","cost.int","coef_noint","coef_death","HR_int"),mean)
#> # A tibble: 16 × 9
#> sensitivity util.sick util.sicker cost.sick cost.sicker cost.int coef_noint
#> <int> <dbl> <dbl> <dbl> <dbl> <dbl> <dbl>
#> 1 1 0.6 0.579 3162. 7968. 1063. -1.62
#> 2 2 0.724 0.3 3162. 7968. 1063. -1.62
#> 3 3 0.724 0.579 1000 7968. 1063. -1.62
#> 4 4 0.724 0.579 3162. 5000 1063. -1.62
#> 5 5 0.724 0.579 3162. 7968. 800 -1.62
#> 6 6 0.726 0.578 3152. 7955. 1066. -2.30
#> 7 7 0.723 0.580 3158. 7972. 1062. -1.62
#> 8 8 0.724 0.579 3161. 7967. 1064. -1.62
#> 9 9 0.9 0.579 3162. 7968. 1063. -1.62
#> 10 10 0.724 0.7 3162. 7968. 1063. -1.62
#> 11 11 0.724 0.579 5000 7968. 1063. -1.62
#> 12 12 0.724 0.579 3162. 9000 1063. -1.62
#> 13 13 0.724 0.579 3162. 7968. 2000 -1.62
#> 14 14 0.725 0.578 3150. 7961. 1067. -0.916
#> 15 15 0.723 0.580 3157. 7972. 1063. -1.62
#> 16 16 0.724 0.579 3161. 7967. 1064. -1.62
#> # ℹ 2 more variables: coef_death <dbl>, HR_int <dbl>Model Execution, Simple PSA
The model is executed as before, just activating the psa_bool option and deactivating the sensitivity_bool and removing sensitivity_names
results <- run_sim(
npats=100,
n_sim=10,
psa_bool = TRUE,
arm_list = c("int", "noint"),
common_all_inputs = common_all_inputs,
common_pt_inputs = common_pt_inputs,
unique_pt_inputs = unique_pt_inputs,
init_event_list = init_event_list,
evt_react_list = evt_react_list,
util_ongoing_list = util_ongoing,
cost_ongoing_list = cost_ongoing,
sensitivity_bool = FALSE,
input_out = unlist(list_par[["parameter_name"]])
)
#> Analysis number: 1
#> Simulation number: 1
#> Time to run simulation 1: 0.32s
#> Simulation number: 2
#> Time to run simulation 2: 0.13s
#> Simulation number: 3
#> Time to run simulation 3: 0.13s
#> Simulation number: 4
#> Time to run simulation 4: 0.12s
#> Simulation number: 5
#> Time to run simulation 5: 0.13s
#> Simulation number: 6
#> Time to run simulation 6: 0.12s
#> Simulation number: 7
#> Time to run simulation 7: 0.13s
#> Simulation number: 8
#> Time to run simulation 8: 0.12s
#> Simulation number: 9
#> Time to run simulation 9: 0.13s
#> Simulation number: 10
#> Time to run simulation 10: 0.13s
#> Time to run analysis 1: 1.47s
#> Total time to run: 1.47s
#> Simulation finalized;Check results
We briefly check below that indeed the engine has been changing the corresponding parameter values.
data_simulation <- bind_rows(map_depth(results,2, "merged_df"))
#Check mean value across iterations as PSA is off
data_simulation |> group_by(simulation) |> summarise_at(c("util.sick","util.sicker","cost.sick","cost.sicker","cost.int","coef_noint","coef_death","HR_int"),mean)
#> # A tibble: 10 × 9
#> simulation util.sick util.sicker cost.sick cost.sicker cost.int coef_noint
#> <int> <dbl> <dbl> <dbl> <dbl> <dbl> <dbl>
#> 1 1 0.528 0.563 5010. 9352. 1073. -1.43
#> 2 2 0.666 0.544 3065. 7914. 808. -1.07
#> 3 3 0.742 0.526 2393. 7690. 1323. -1.99
#> 4 4 0.727 0.767 2491. 8069. 1009. -1.34
#> 5 5 0.808 0.570 4021. 7834. 1026. -1.93
#> 6 6 0.874 0.501 1881. 6913. 1158. -2.01
#> 7 7 0.859 0.457 2730. 9349. 1264. -1.70
#> 8 8 0.935 0.438 3954. 6225. 813. -1.35
#> 9 9 0.886 0.648 3104. 7909. 695. -1.75
#> 10 10 0.870 0.576 3952. 6264. 1176. -1.52
#> # ℹ 2 more variables: coef_death <dbl>, HR_int <dbl>